集群弹性伸缩是如何运作的。小编来告诉你更多相关信息。
集群弹性伸缩是如何运作的
为大家说一说集群弹性伸缩是如何运作的的话题,具体介绍如下:
弹性伸缩 可以根据用户实际需求调整计算资源(算力)的多寡,可以说这是每个厂商必备的能力,比如腾讯云 AS、Amazon EC2 Auto Scaling、Azure Autoscale、Google MIG、阿里云 ESS 等等。
集群弹性伸缩 作用于 kubernetes 集群中,功能上与弹性伸缩保持一致,两者最大的差异是衡量资源需求量的标准。
弹性伸缩常常以实际负载作为扩缩依据,而集群弹性伸缩是以资源分配占比作为依据,为 workload 分配资源往往需要我们对自身的业务具有相对合理的认识。
CA 可以根据集群实际使用情况,为集群增加或者减少节点:
- 当有Pod由于资源不足而不可调度时,考虑扩容
- 当有节点资源利用率不高时,考虑缩容
- repo:https://github.com/alphajc/autoscaler/tree/master/cluster-autoscaler
- FAQ:https://github.com/alphajc/autoscaler/blob/master/cluster-autoscaler/FAQ.md
与 HPA、HPC 的关系
在 kubernetes 中有关 HPA 的介绍可以移步官方文档,HPA 可以根据实际负载调整 workload 的副本数,即 Pod 数量,如果调升后计算资源不足就会导致 Pod Pending,调降后资源过剩就会导致节点闲置。
尽量保证 Pending 的节点得到调度,闲置的节点得到释放,就是 CA (cluster-autoscaler 简称) 的作用。
CA + HPA 与云厂商的弹性伸缩功能大致相当。
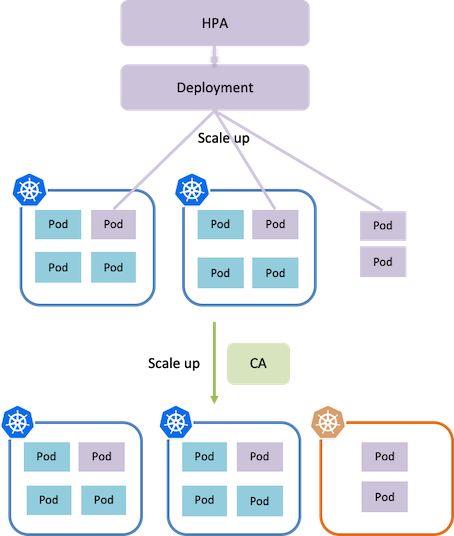
根据负载得到的资源需求往往具有一定的滞后性,触发扩容时或多或少都已经影响到了业务,所以云厂商提供的弹性伸缩一般还具有定时伸缩的能力。
TKE 团队提供的 HPC 可以定时调整 workload 的副本数,其与 CA 配合就可以达到集群节点定时伸缩的效果了。
使用须知
- CA 一般基于云厂商提供的弹性伸缩功能实现 NodeGroup,但其伸缩机制有冲突,故不可在集群中的启用原弹性机制
- 开启集群弹性伸缩的集群中的 workload 务必指定 request
- NodeGroup 中配置的机型资源充足
- 当单节点池配置了多可用区的子网时,含可用区亲和性调度的扩容会有异常
- 不支持单节点池多规格机型
实现逻辑
CA 的代码主体是一个无限循环,通过一次次的扫描集群,根据集群当前状态决策和执行扩缩容。
具体的循环间隔通过 –scan-interval 参数控制,默认为 10s,一张图带你理解扩缩容全流程:
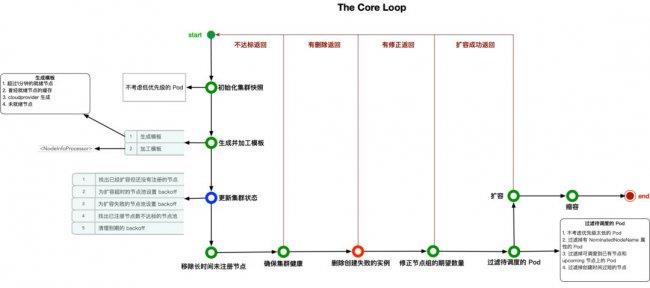
- 集群快照 ClusterSnapshot 中,会存储所有节点和非低优的 Pod
集群弹性伸缩是如何运作的。小编来告诉你更多相关信息。
集群弹性伸缩是如何运作的
- 生成加工出来的模板用于扩容,将在后续扩容专题中细讲
- 更新集群状态的主要目的是:
- 找出已经触发扩容但还没有注册的节点
- 为扩容超时节点对应的节点池设置 backoff
- 查询创建失败的节点,设置对应节点池为 backoff
- 找出当前已注册节点数不在可接受区间内的节点池
- 清理 backoff
- 长时间没有注册上的节点会被删除,时间由 –max-node-provision-time 指定,默认为 15min
- 只有当集群是健康时,CA 才会实际扩缩容,否则循环会直接返回
- 删除在更新集群状态时找到的创建失败的节点
- 当已经注册的实例数长时间小于期望实例数时,会将节点池的期望实例数调整为已注册实例数,时间由 –max-node-provision-time 指定,默认为 15min
- 过滤掉一些不需要触发扩容的 pod
- 不考虑优先级太低的 Pod,–expendable-pods-priority-cutoff 指定,默认为 -10
- 过滤掉有 NominatedNodeName 属性的 Pod
- 过滤掉可调度到已有节点和 upcoming 节点上的 Pod
- 过滤掉创建时间过短的节点,时间由 –new-pod-scale-up-delay 指定,默认为 0,即不过滤
- 过滤掉创建时间短于 2s 的 pod,或者短于 30s 的 gpu pod
- 扩容将在后续扩容专题中细讲
- 缩容将在后续缩容专题中细讲
集群健康认定:
当集群同时满足下述两个条件时,集群会被认为是异常的,反之健康:
- 未就绪的 Node 数大于启动参数中 —-ok-total-unready-count 指定值(默认 3)
- 未就绪的 Node 数占总 Node 数百分比大于 —-max-total-unready-percentage 指定值(默认 45)
当集群不健康时,在会在 kube-system 下记录一个 ClusterUnhealthy 的事件。
扩容中节点(Upcoming Nodes)
扩容中实例数 = 期望实例数 – (就绪实例数 + 未就绪实例数 + 长时间未注册的实例数)
- 期望实例数:节点池当前期望的实例数
- 就绪实例数:节点池在集群中已经就绪可用的实例数
- 未就绪实例数:已经注册到集群但还不可用的实例数
- 未注册实例数:通过 cloudprovider 可以查到,但是在集群中还查不到的实例数
- 已删除的实例数:被打上 ToBeDeletedByClusterAutoscaler 污点的实例数
- 长时间未注册的实例数:存在时间超过 —-max-node-provision-time 的未注册实例数
上述分享的集群弹性伸缩是如何运作的的全面介绍了,希望给网的网友们带来一些相关知识。